
第八届“强网”拟态防御国际精英挑战赛 Misc writeup
Misc
标准的绝密压缩
流量包 可以看到传了一堆 8950 的字符串 转一下就是png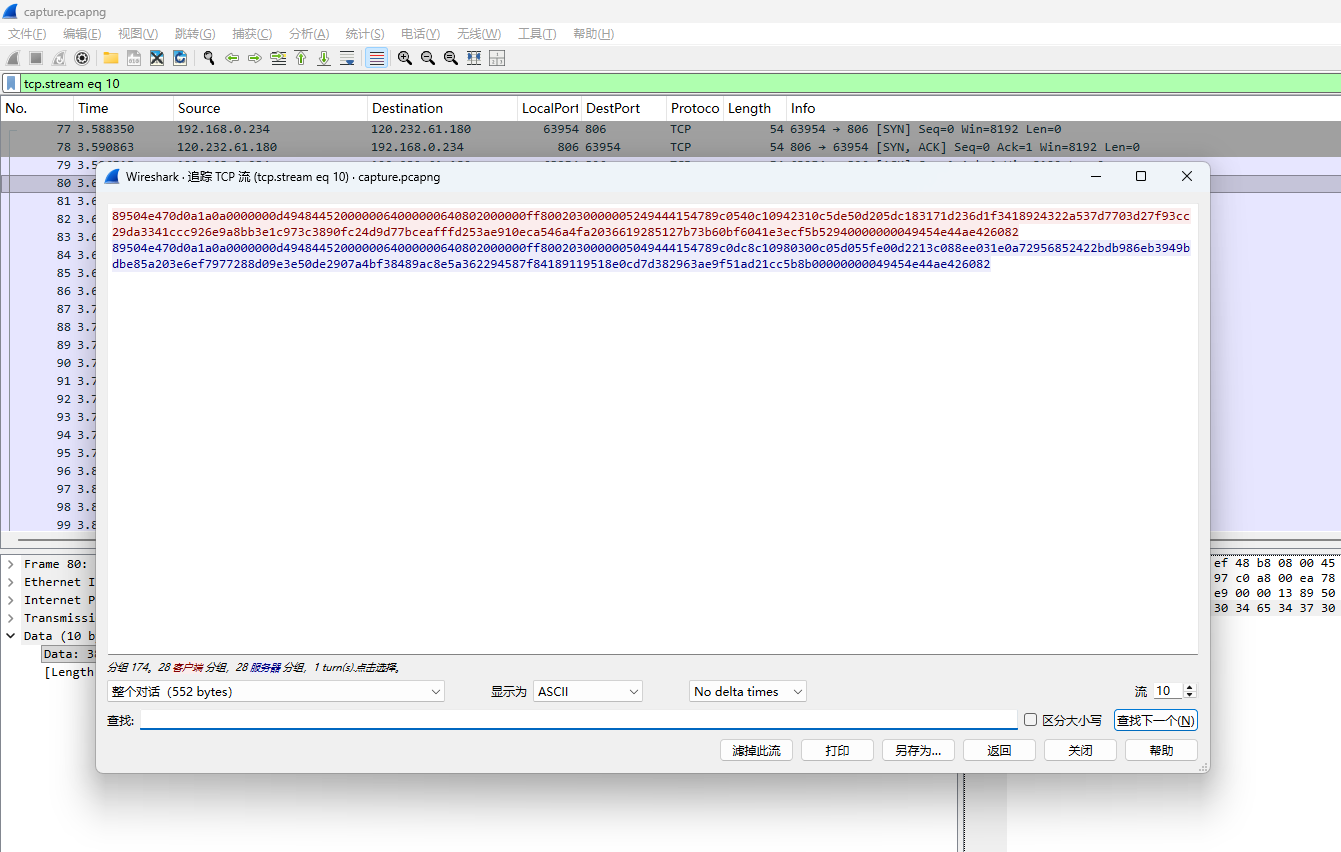
tshark 导出所有的 tcp 流
tshark -r capture.pcapng -Y "tcp" -T fields -e data > tcpStreams.txt
然后提取出所有的 png 数据 一共有三十张
对png的idat块进行zlib解压 可以得到明文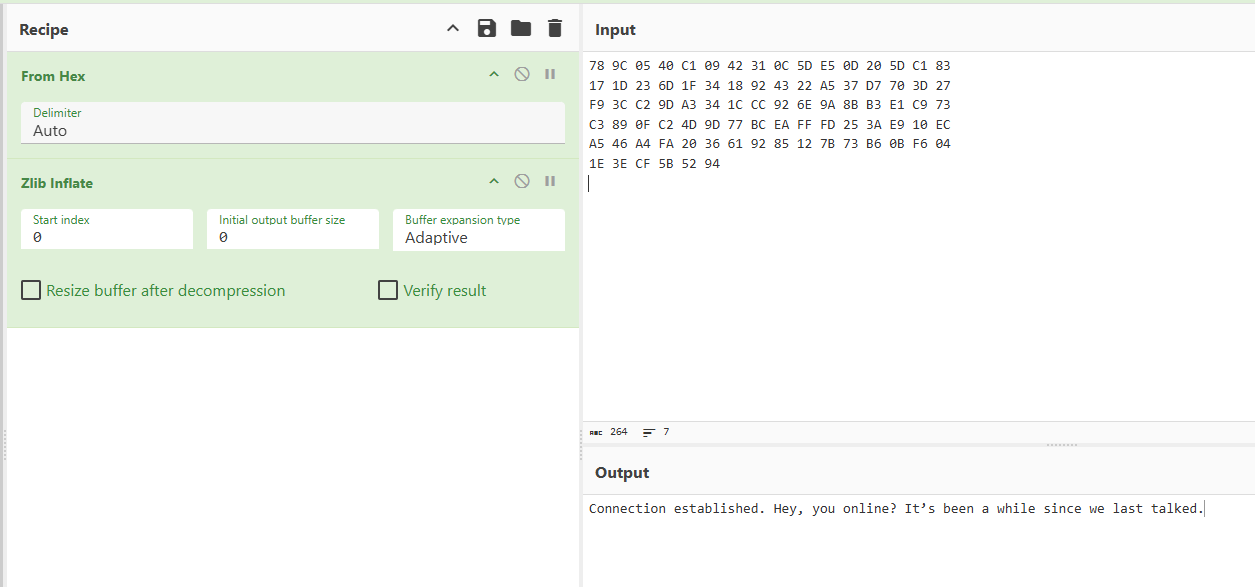
写脚本对所有png进行处理 得到完整的对话
Connection established. Hey, you online? It’s been a while since we last talked.
Yeah, I’m here. Busy as always. Feels like the days are getting shorter.
Tell me about it. I barely have time to sleep lately. Between maintenance logs and incident reports, I’m drowning.
Sounds rough. I’ve been buried in audits myself. Every time I finish one, another pops up.
Classic. Sometimes I wonder if the machines are easier to deal with than the people.
No kidding. At least machines don’t ask pointless questions.
True. Anyway, before I forget—how’s that side project you were working on? The one you wouldn’t shut up about months ago.
Still alive… barely. Progress is slow, but steady. You know me—I don’t give up easily.
Good. I hope it pays off one day.
Thanks. Alright… I’m guessing you didn’t ping me just to chat?
Well, half of it was. It’s been a while. But yes—I do have something for you today. Before sending the core cipher, I’ll transmit an encrypted archive first. It contains a sample text and the decryption rules.
Okay. What’s special about this sample text?
And… inside the sample text, I used my favorite Herobrine legend—you know the one I always bring up.
Of course I know. The hidden original text from that weird old site, right?
What can I say—old habits die hard. Anyway, the important part: the sample packet and the core cipher are encrypted with the same password.
Got it. So if I can decrypt the sample, the real one should be straightforward.
Exactly. Send the sample when ready.
I’m ready. Go ahead.
UEsDBBQAAQAIABtFeFu1Ii0dcwAAAHwAAAAJAAAAcnVsZXMudHh07XuRBFDbojGKhAz59VaKEpwD6/rKaZnqUxf+NMH0rybWrAMPewZ/yGyLrMKQjNIcEbPAxjmP5oTh8fP77Vi1wnFwzN37BmrQ9SCkC27FC/xeqbgw/HWcDpgzsEoiNpqT9ZThrbAScyg5syfJmNactjelNVBLAwQUAAEACACGOXhbpdvG1ysBAAAVAgAACgAAAHNhbXBsZS50eHTA1fy4cMLZwZkTI1mEk88yOXy9rmbTbCNBQOo9hqKQPK6vjZVo9aCtTVflmkKYGV99+51qXbinmG7WGik5UvLJk9MKRosThBCDMHrmjibOCzjzNELwEgEyX8DjqJkSc8pIFwj+oRM3bb4i0GtRxbwqgsxCtgwiKdCVoXVdetN7RKLIQ7DD+Huv/ZptNdd0yRNHis9LEA3loB+IHZ+dK7IknqPh4lYF8JwAjx5/wwp0YAM6Bcec7uAvk6B5t1pEztm1rLl8TjniVz5/bBUTo1LjUXnar/pnm1NvE9EAuxz/s6b+O8/ew7/A4ItdNJGzDudh6YULfiV3pCTXFIbR4GCe4LwkohWZIlAjysA+zLRrgkTDoB10vWdNGdfoBAlLRoUdZ95mS7X5/bXV41BLAQI/ABQAAQAIABtFeFu1Ii0dcwAAAHwAAAAJACQAAAAAAAAAIAAAAAAAAABydWxlcy50eHQKACAAAAAAAAEAGABIv3f82lzcAQAAAAAAAAAAAAAAAAAAAABQSwECPwAUAAEACACGOXhbpdvG1ysBAAAVAgAACgAkAAAAAAAAACAAAACaAAAAc2FtcGxlLnR4dAoAIAAAAAAAAQAYAFP0sZjOXNwBAAAAAAAAAAAAAAAAAAAAAFBLBQYAAAAAAgACALcAAADtAQAAAAA=
got it. Decrypting… yeah, it works.
Good. That means the channel is stable.
Alright. Whenever you’re ready, send the real thing.
The core cipher will be transmitted through our secret channel. You remember how to decrypt it, right?
Of course. I’ve got the procedure ready. Start when you’re ready.
Done. Core cipher fully received. Integrity verified—no corruption.
Same to you. And hey… nice talking again.
Agreed. Take care.
Good. Keep things quiet for the next few days.
Yeah. Let’s not wait so long next time.
You too.
解码对话中的Base64 得到压缩包
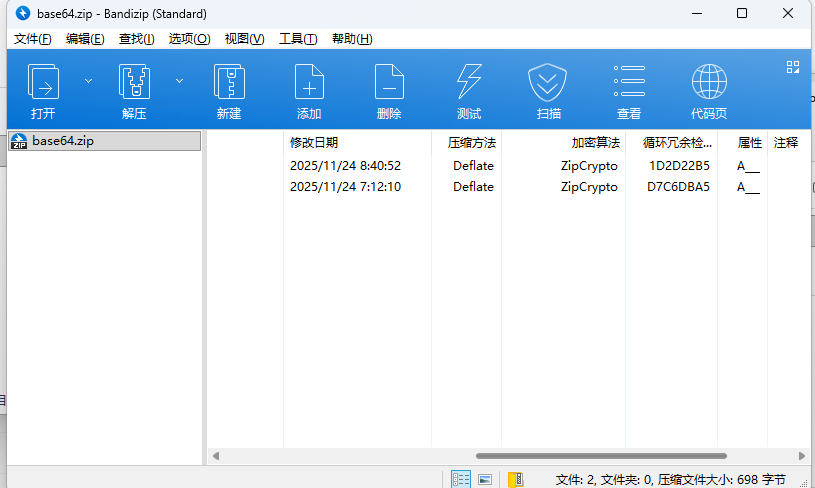
一个包含两个文件 用ZipCrypto算法加密的压缩包 一眼明文攻击 结合对话中提到的
Of course I know. The hidden original text from that weird old site, right?Herobrine 是 Minecraft 游戏中的都市传说 wiki可以查到
对应的内容就是下方的
It has been reported that some victims of torture, during the act, would retreat into a fantasy world from which they could not WAKE UP. In this catatonic state, the victim lived in a world just like their normal one, except they weren't being tortured. The only way that they realized they needed to WAKE UP was a note they found in their fantasy world. It would tell them about their condition, and tell them to WAKE UP. Even then, it would often take months until they were ready to discard their fantasy world and PLEASE WAKE UP.
算一下CRC32
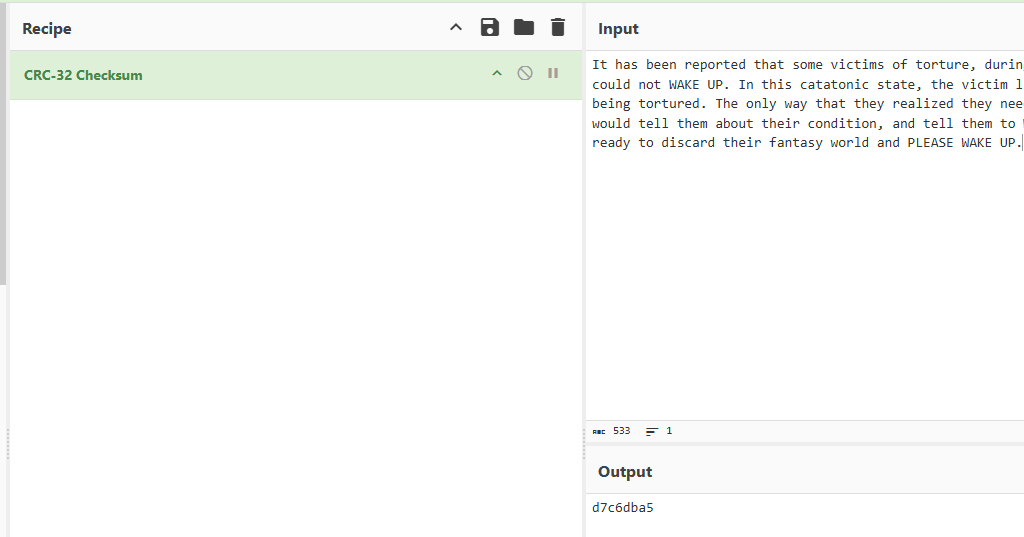
与压缩包中sample.txt一致,作为明文进行攻击
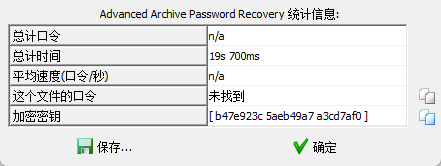
得到加密密钥 解密出 rule.txt
1.you need to calc the md5 of port to decrypt the core data.
2.The cipher I put in the zip, in segments, has been deflated.
两条线索 =>
1. 端口的md5作为位置加密的密码
1. 密文在压缩包中 被分片deflated解压传输了
继续翻流量包
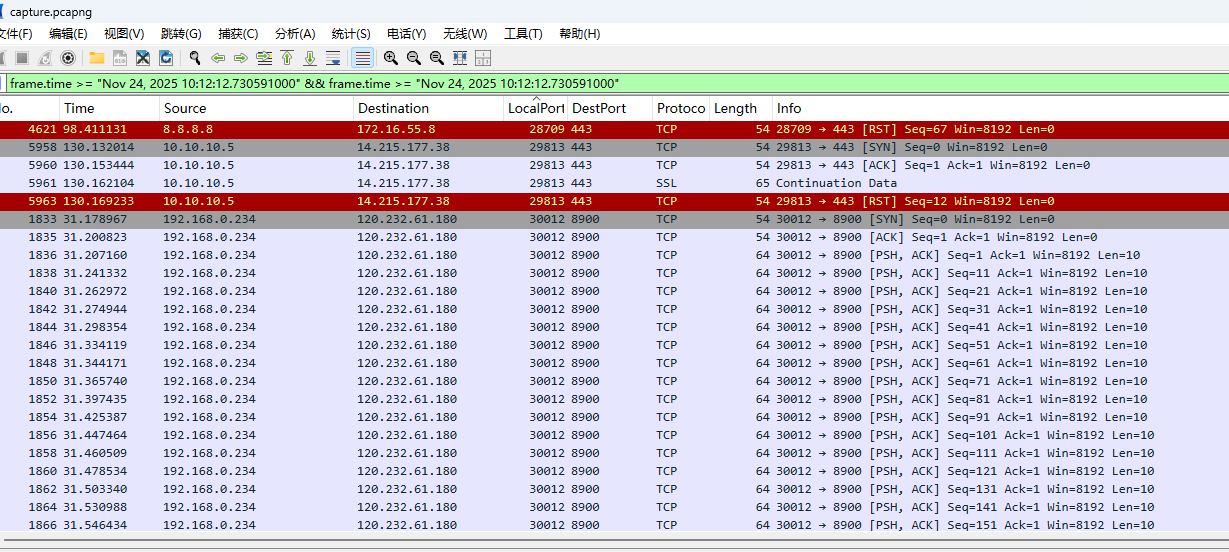
可以观察到 从端口30012到30091 一直在tcp传输数据
提取出一个流的数据 使用端口的md5作为密码 进行AES-ECB解密
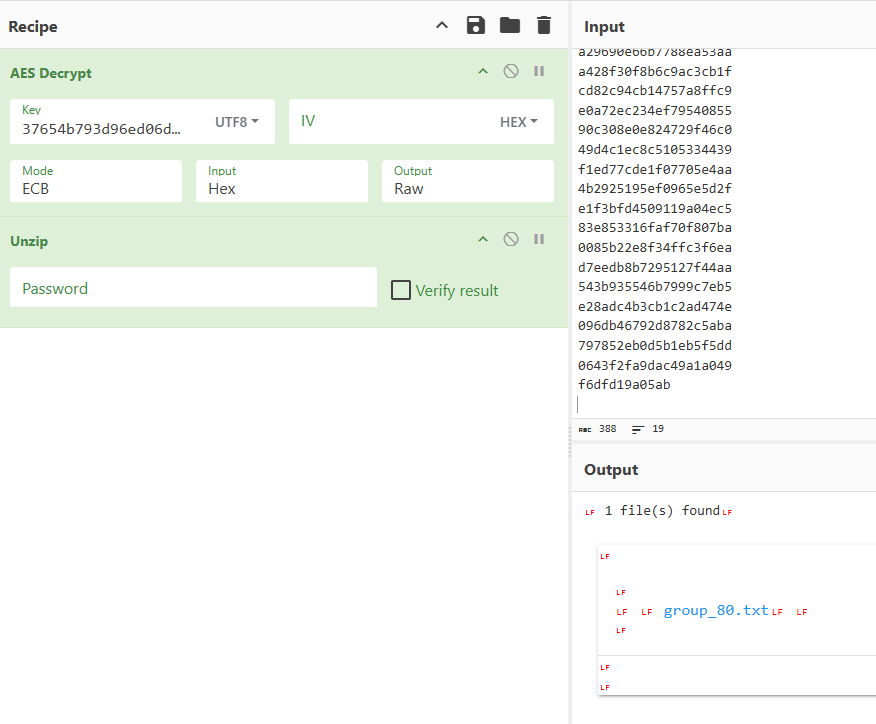
可以解析出zip 编写脚本提取所有符合规则的tcp流然后解密
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import hashlib
from collections import OrderedDict
from pathlib import Path
from scapy.all import rdpcap, IP, TCP, Raw
from Crypto.Cipher import AES
SRC_IP = "192.168.0.234"
PORT_MIN = 30012
PORT_MAX = 30091
ZIP_MAGIC = b"PK\x03\x04"
def load_flows(pcap_path):
packets = rdpcap(pcap_path)
flows = OrderedDict()
for pkt in packets:
if not (IP in pkt and TCP in pkt and Raw in pkt):
continue
ip = pkt[IP]
tcp = pkt[TCP]
if ip.src != SRC_IP:
continue
if not (PORT_MIN <= tcp.sport <= PORT_MAX):
continue
key = (ip.src, tcp.sport, ip.dst, tcp.dport)
flows.setdefault(key, bytearray()).extend(bytes(pkt[Raw].load))
print(f"[+] 找到 {len(flows)} 条 TCP 流")
return flows
def aes_ecb_decrypt(data: bytes, port: int) -> bytes:
# AES Key = MD5 Hex(UTF-8), 32 字节,用作 AES-256
hexkey = hashlib.md5(str(port).encode()).hexdigest() # 32 字节字符串
key = hexkey.encode('utf-8') # 32 字节 key → AES-256
# PKCS7 不一定有,所以只补齐到 16 字节长度
if len(data) % 16 != 0:
data += b"\x00" * (16 - (len(data) % 16))
cipher = AES.new(key, AES.MODE_ECB)
return cipher.decrypt(data)
def extract_zip(data: bytes) -> bytes:
idx = data.find(ZIP_MAGIC)
if idx == -1:
return b""
return data[idx:]
def process_pcap(pcap_path: str):
flows = load_flows(pcap_path)
output_dir = Path("out")
output_dir.mkdir(exist_ok=True)
port_count = {}
for (src, sport, dst, dport), payload in flows.items():
print(f"[+] 解密 {sport} 流,长度 {len(payload)}")
decrypted = aes_ecb_decrypt(bytes(payload), sport)
zip_data = extract_zip(decrypted)
if not zip_data.startswith(ZIP_MAGIC):
print(f"[!] 端口 {sport} 未找到 ZIP Header,跳过")
continue
cnt = port_count.get(sport, 0)
port_count[sport] = cnt + 1
suffix = f"_{cnt}" if cnt > 0 else ""
out_path = Path("out") / f"{sport}{suffix}.zip"
with open(out_path, "wb") as f:
f.write(zip_data)
print(f"[+] 已写入 {out_path}")
print("[+] 处理完毕")
def main():
process_pcap("capture.pcapng")
if __name__ == "__main__":
main()
得到一堆压缩包
观察压缩包 可以发现内容都是4字节的txt 直接进行不可见字符的crc32爆破
脚本如下
import os
import zipfile
import binascii
# ---------------- CRC32 REVERSE CLASS (your original code) -------------------
class CRC32Reverse:
def __init__(self, crc32, length, tbl=bytes(range(256)), poly=0xEDB88320, accum=0):
self.char_set = set(tbl)
self.crc32 = crc32
self.length = length
self.poly = poly
self.accum = accum
self.table = []
self.table_reverse = []
def init_tables(self, poly, reverse=True):
for i in range(256):
for j in range(8):
if i & 1:
i >>= 1
i ^= poly
else:
i >>= 1
self.table.append(i)
if reverse:
for i in range(256):
found = [j for j in range(256) if self.table[j] >> 24 == i]
self.table_reverse.append(tuple(found))
def calc(self, data, accum=0):
accum = ~accum
for b in data:
accum = self.table[(accum ^ b) & 0xFF] ^ ((accum >> 8) & 0x00FFFFFF)
accum = ~accum
return accum & 0xFFFFFFFF
def find_reverse(self, desired, accum):
solutions = set()
accum = ~accum
stack = [(~desired,)]
while stack:
node = stack.pop()
for j in self.table_reverse[(node[0] >> 24) & 0xFF]:
if len(node) == 4:
a = accum
data = []
node = node[1:] + (j,)
for i in range(3, -1, -1):
data.append((a ^ node[i]) & 0xFF)
a >>= 8
a ^= self.table[node[i]]
solutions.add(tuple(data))
else:
stack.append(((node[0] ^ self.table[j]) << 8,) + node[1:] + (j,))
return solutions
def dfs(self, length, outlist=[b'']):
if length == 0:
return outlist
tmp_list = [item + bytes([x]) for item in outlist for x in self.char_set]
return self.dfs(length - 1, tmp_list)
def run_reverse(self):
self.init_tables(self.poly)
desired = self.crc32
accum = self.accum
result_list = []
if self.length >= 4:
patches = self.find_reverse(desired, accum)
for item in self.dfs(self.length - 4):
patch = list(item)
patches = self.find_reverse(desired, self.calc(patch, accum))
for last4 in patches:
patch.extend(last4)
if self.calc(patch, accum) == desired:
result_list.append(bytes(patch))
else:
for item in self.dfs(self.length):
if self.calc(item) == desired:
result_list.append(bytes(item))
return result_list
def crc32_reverse(crc32, length, char_set=bytes(range(256)), poly=0xEDB88320, accum=0):
return CRC32Reverse(crc32, length, char_set, poly, accum).run_reverse()
# ---------------------- MAIN ZIP SCAN ------------------------
def scan_zip_crc(dirname, output_bin="output.bin", brute_length=4):
results = []
for root, dirs, files in os.walk(dirname):
for fname in files:
if fname.lower().endswith(".zip"):
zip_path = os.path.abspath(os.path.join(root, fname))
zip_path = zip_path.replace("\\", "/")
print(f"[+] 发现压缩包:{zip_path}")
try:
with zipfile.ZipFile(zip_path) as z:
for info in z.infolist():
crc = info.CRC
print(f" → 文件头:{info.filename} CRC32={crc:08X}")
res = crc32_reverse(crc, brute_length)
print(f" 逆推得到 {len(res)} 条结果")
results.extend(res)
except Exception as e:
print(f"[-] 无法读取 ZIP:{zip_path}, 错误:{e}")
# 写入 bin
with open(output_bin, "wb") as f:
for r in results:
f.write(r)
print(f"[+] 已写入 {len(results)} 条结果 → {output_bin}")
if __name__ == "__main__":
scan_zip_crc("./out", output_bin="final_output.bin", brute_length=4)
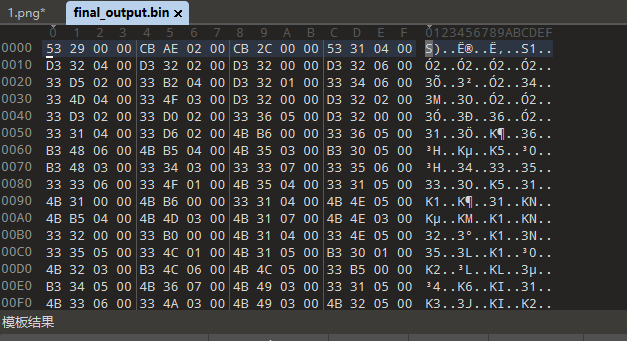
按照每4字节区分,结合上面rule.txt中的线索2 进行一次 Raw Inflate
可以得到密文
$pkzip$1*1*2*0*35*29*4135a7f*0*26*0*35*0413*c8358ce9e6858f166753637de145d0c841cee9efd7cf2008d13e551dd584b69cae5895c7df45f32fdfb51d0c0d273820239896d3e6*$/pkzip$
通过 ZIP 加密哈希字符串 + 已知密码,在文件足够小,ZipCrypto的条件下可以还原出实际文件内容,原理不赘述
结合上方对话中提到的,加密密码相同
Anyway, the important part: the sample packet and the core cipher are encrypted with the same password.
改下橘子的脚本 使用明文攻击得到的keystream进行解密
# -*- coding: utf-8 -*-
import sys
import binascii
import zlib
#############################################
# ZipCrypto 支持内部 key 解密 + 密码解密
#############################################
class ZipCrypto:
def __init__(self, password=None, keys=None):
self.init_crc_table()
if keys:
# 使用用户提供的 3 个内部 key(无需密码)
self.keys = keys[:]
else:
# 使用密码初始化 key
self.keys = [0x12345678, 0x23456789, 0x34567890]
for char in password:
self.update_keys(ord(char))
def init_crc_table(self):
self.crc_table = [0] * 256
for i in range(256):
c = i
for _ in range(8):
c = (0xEDB88320 ^ (c >> 1)) if c & 1 else (c >> 1)
self.crc_table[i] = c & 0xFFFFFFFF
def crc32(self, old_crc, char):
return (self.crc_table[(old_crc ^ char) & 0xFF] ^ (old_crc >> 8)) & 0xFFFFFFFF
def update_keys(self, char):
self.keys[0] = self.crc32(self.keys[0], char)
self.keys[1] = (self.keys[1] + (self.keys[0] & 0xFF)) & 0xFFFFFFFF
self.keys[1] = (self.keys[1] * 134775813 + 1) & 0xFFFFFFFF
self.keys[2] = self.crc32(self.keys[2], (self.keys[1] >> 24) & 0xFF)
def decrypt_byte(self):
temp = (self.keys[2] | 3) & 0xFFFFFFFF
return ((temp * (temp ^ 1)) >> 8) & 0xFF
def decrypt(self, ciphertext):
plain = bytearray()
for byte in ciphertext:
k = self.decrypt_byte()
p = byte ^ k
self.update_keys(p)
plain.append(p)
return plain
################################################
# 辅助函数
################################################
def get_hex_part_by_len(parts, target_len):
for p in parts:
if len(p) == target_len and all(c in "0123456789abcdefABCDEF" for c in p):
return p
return None
def get_max_hex_part(parts, exclude=None):
hex_payload = ""
max_len = 0
for p in parts:
if exclude and p == exclude:
continue
if len(p) > max_len and all(c in "0123456789abcdefABCDEF" for c in p):
hex_payload = p
max_len = len(p)
return hex_payload
def smart_output(data, label):
print("-" * 50)
method = "Unknown"
final_output = b""
try:
final_output = zlib.decompress(data, -15)
method = "Deflated (Compressed)"
except Exception:
final_output = data
method = "Stored (Uncompressed)"
print(f"[*] Data Mode: {method}")
try:
print(final_output.decode("utf-8"))
except:
print(final_output.decode("utf-8", errors="replace"))
print(f"Hex Preview: {binascii.hexlify(final_output)[:60]}...")
filename = f"flag_{label}.bin"
with open(filename, "wb") as f:
f.write(final_output)
print(f"[*] Saved to: {filename}")
print("-" * 50)
################################################
# 解密 ZIPCrypto(仅 $pkzip$ / $pkzip2$)
################################################
def recover_zipcrypto(hash_str, password=None, keys=None):
print("[*] 解析 ZipCrypto Hash")
clean_hash = hash_str.strip()
tag = "$pkzip2$" if "$pkzip2$" in clean_hash else "$pkzip$"
clean_hash = clean_hash.replace(tag, "").replace(f"/{tag.replace('$','')}", "")
parts = clean_hash.split('*')
payload_hex = get_max_hex_part(parts)
if not payload_hex:
print("[!] 无法找到密文字段")
return
encrypted_bytes = binascii.unhexlify(payload_hex)
print(f"[*] 密文长度: {len(encrypted_bytes)} bytes")
if keys:
print("[+] 使用内部 key 解密(无需密码)")
zc = ZipCrypto(keys=keys)
else:
print("[+] 使用密码解密")
zc = ZipCrypto(password=password)
decrypted = zc.decrypt(encrypted_bytes)
if len(decrypted) <= 12:
print("[!] 解密结果不足 12 字节,非法 ZIPCrypto 结构")
return
# 去掉 12 字节 header
smart_output(decrypted[12:], "zipcrypto")
################################################
# 主入口
################################################
if __name__ == "__main__":
my_hash = '$pkzip$1*1*2*0*35*29*4135a7f*0*26*0*35*0413*c8358ce9e6858f166753637de145d0c841cee9efd7cf2008d13e551dd584b69cae5895c7df45f32fdfb51d0c0d273820239896d3e6*$/pkzip$'
k0 = int("b47e923c", 16)
k1 = int("5aeb49a7", 16)
k2 = int("a3cd7af0", 16)
recover_zipcrypto(my_hash, keys=[k0, k1, k2])
得到flag
泄露的时间与电码
解密脚本
import math
# 与题目中 SecureTypewriter 的参数保持一致
TIME_UNIT = 0.005
JITTER = 0.001
BASE_OVERHEAD = 10
BRANCH_PENALTY = 30
# ------------- LFSR 生成密钥流(逐字节) -------------
def lfsr_stream(n, seed=0x92):
"""
复现题目里的 8-bit LFSR:
bit = (b0 ^ b2 ^ b3 ^ b4) & 1
lfsr = (lfsr >> 1) | (bit << 7)
每次 yield 当前 lfsr(作为密钥字节)
"""
lfsr = seed
for _ in range(n):
bit = ((lfsr >> 0) ^ (lfsr >> 2) ^ (lfsr >> 3) ^ (lfsr >> 4)) & 1
lfsr = (lfsr >> 1) | (bit << 7)
yield lfsr
# ------------- 预测给定 base_ops 的理论时间 -------------
def predicted_time(base_ops: int) -> float:
"""
根据 base_ops 计算理论执行时间(不含噪声),
与题目中 process_char 里的 current_ops / real_duration 对应。
"""
current_ops = BASE_OVERHEAD + base_ops
if base_ops % 2 != 0:
current_ops += BRANCH_PENALTY
return current_ops * TIME_UNIT
# ------------- 从单个时间点反推出 base_ops -------------
def recover_base_ops(t: float) -> int:
"""
暴力枚举 base_ops ∈ [0,255],计算其理论时间,
取与测量时间 t 差值最小的那个 base_ops。
因为 jitter(±0.001) 远小于一个 op(0.005),
正确值应该非常明显。
"""
best_ops = 0
best_diff = float("inf")
for base_ops in range(256):
dt = abs(predicted_time(base_ops) - t)
if dt < best_diff:
best_diff = dt
best_ops = base_ops
# 如有需要可以加一个阈值检查,比如 best_diff > 0.002 时报警
return best_ops
# ------------- 逆向 scramble:base_ops -> val -------------
def invert_scramble(base_ops: int) -> int:
"""
原题:base_ops = (val * 0x1F + 0x55) & 0xFF
在 mod 256 上:
base_ops ≡ 31 * val + 0x55 (mod 256)
val ≡ (base_ops - 0x55) * inv(31) (mod 256)
其中 inv(31) = 0xDF = 223(因为 31*223 ≡ 1 mod 256)
"""
return (((base_ops - 0x55) & 0xFF) * 0xDF) & 0xFF
# ------------- 主逻辑:从 timing.log 还原 flag -------------
def main():
# 1. 读取 timing.log 中的时间序列
timings = []
with open("timing.log", "r") as f:
for line in f:
line = line.strip()
if not line:
continue
timings.append(float(line))
n = len(timings)
# 2. 生成与字符数相同长度的 LFSR 密钥流
keystream = list(lfsr_stream(n))
# 3. 对每个时间点反推 base_ops -> val -> 原始字符 c
chars = []
for t, k in zip(timings, keystream):
base_ops = recover_base_ops(t) # 从时间反推 base_ops
val = invert_scramble(base_ops) # 逆向 scramble 得到 val
c = val ^ k # val = c ^ k -> c = val ^ k
chars.append(chr(c))
flag = "".join(chars)
print("Recovered flag:")
print(flag)
if __name__ == "__main__":
main()
侧信道攻击
侧信道攻击指:利用算法的执行时间差异、功耗差异、电磁信息、缓存访问行为等非加密输出的信息,来间接推测“秘密”。
加密代码中 base_ops 的奇偶会导致约0.15秒时间差 与0.001秒的噪声相比极大 逆元异或就能恢复明文
Recovered flag:
h i j k l m n
8 9 0 / - _ =
a b c d e f g
v w x y z { }
o p q r s t u
1 2 3 4 5 6 7
使用 steg86 二进制文件隐写提取密文 https://github.com/woodruffw/steg86

得到
2j10l kkhh :3 $ jhh 4h 2k2h $3j 4h3k j20h jj6l kkll llk ^j kk$hh 0jj /z :6 5k$ jj j
jlkh对应的是vim中的方向键 H← J↑ K↓ L→
初始位置为(0,0) => h 按照方向和数量依次移动选取矩阵中的字符即可得到flag
注意中间的空格也算字符
flag{y0u-are_amaz1ng}
返璞归真
传统misc
压缩包伪加密 备注提示hashisk3y 解压得到一张图片, foremost提取出bmp文件
paperbak http://www.ollydbg.de/Paperbak/
提取出wow.txt 长度是23字节
jNX+xu2QKBm23AUlwClt+3xDkQcJGjM=
结合提示hashisk3y 用foremost分离出的jpg的md5作为密码 对密文进行rc4解密
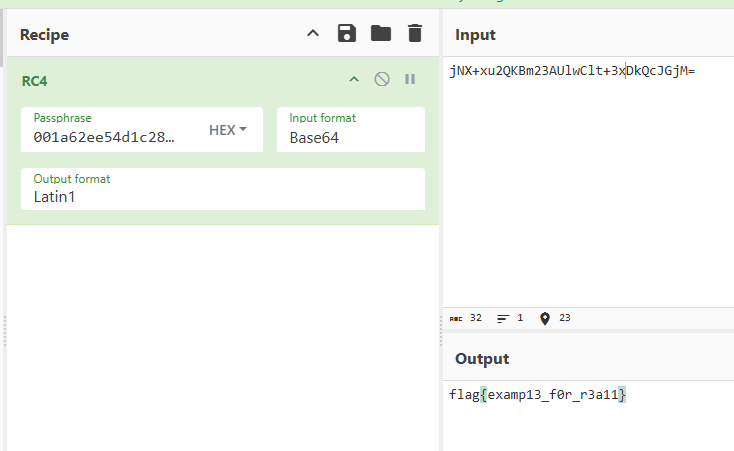
得到flag
猫咪电台
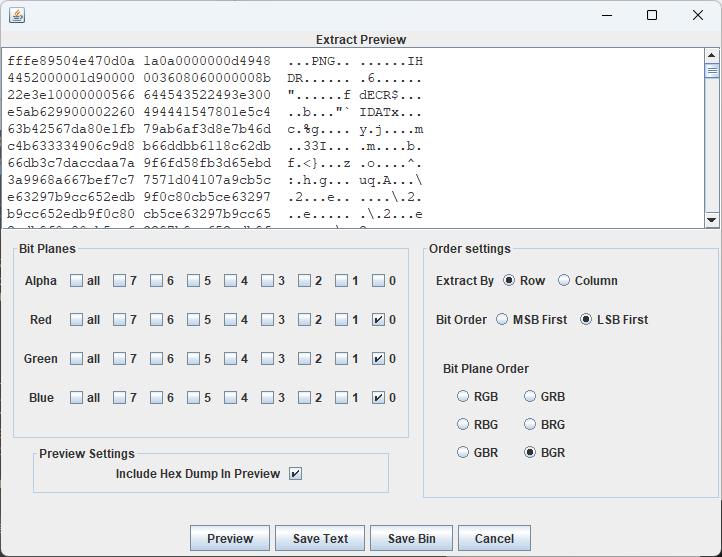
cat0.png存在lsb LSB优先 BGR 分理出图片 得到flag part0

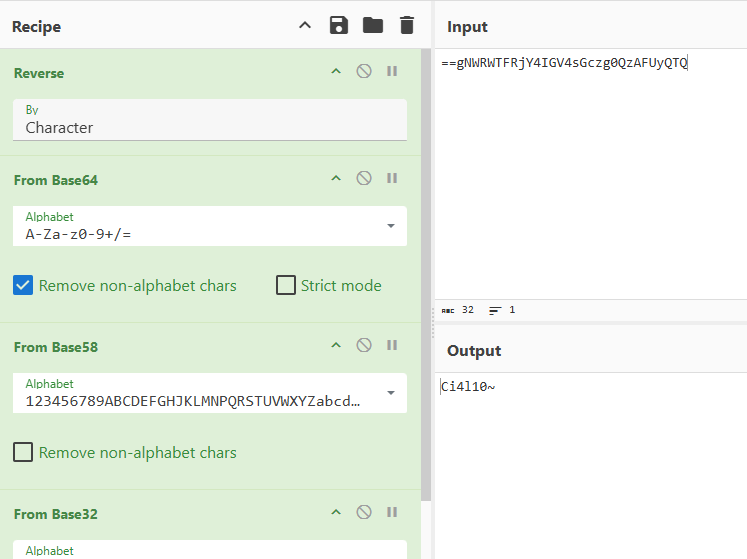
结合题目中的电台
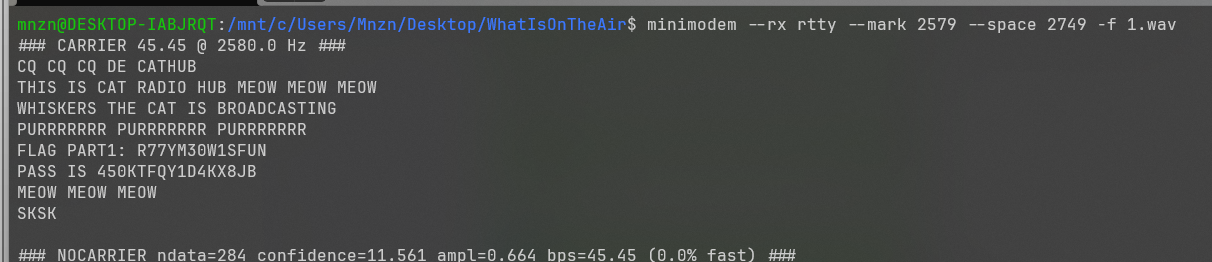
使用Minimodem对wav进行解调 得到flag part1
用密码解密zip,得到2.wav 分析一下波形
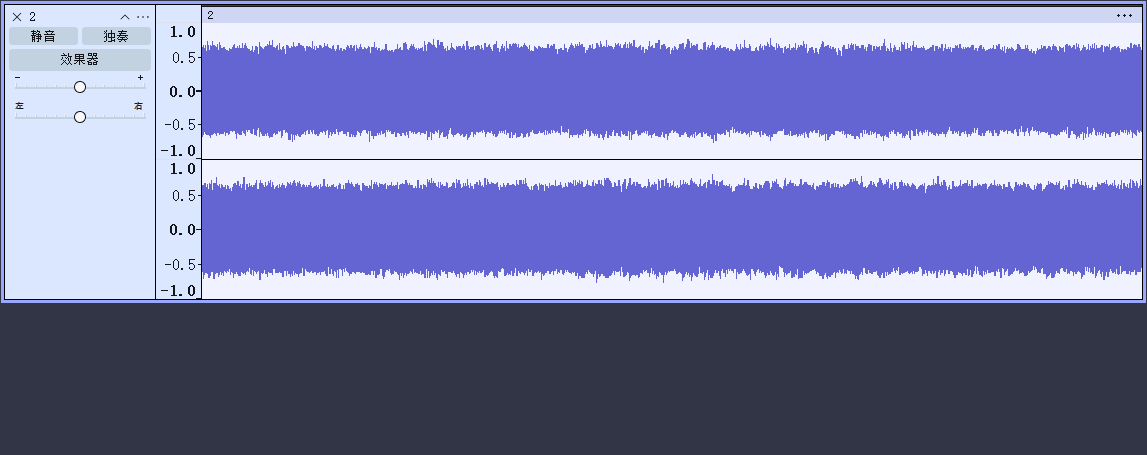
双声道 听起来很乱像噪音 结合题目中的电台 尝试解调
#!/usr/bin/env python3
import numpy as np
import soundfile as sf
from scipy.signal import decimate, firwin, lfilter
input_file = "2.wav"
output_file = "nfm_output.wav"
target_fs = 48000 # 最终音频采样率
def find_peak_frequency(iq, fs):
"""FFT 频谱扫描找到最大能量频率"""
N = len(iq)
window = np.hanning(N)
spectrum = np.fft.fftshift(np.fft.fft(iq * window))
freqs = np.fft.fftshift(np.fft.fftfreq(N, d=1/fs))
peak_idx = np.argmax(np.abs(spectrum))
return freqs[peak_idx]
def fm_demod(iq):
"""窄带 FM 解调"""
# 相位差法
phase = np.angle(iq)
diff = np.diff(np.unwrap(phase))
# 归一化 (防止过大)
demod = diff / np.pi
return demod
def main():
print("读取 IQ 文件:", input_file)
data, fs = sf.read(input_file)
# IQ 为 2 通道: I = left, Q = right
I = data[:, 0]
Q = data[:, 1]
iq = I + 1j * Q
print(f"采样率: {fs} Hz")
print("扫描频谱...")
peak_freq = find_peak_frequency(iq, fs)
print("最强信号峰值频率:", peak_freq, "Hz")
# --- 将信号搬移到 0 Hz ---
print("频率搬移中...")
t = np.arange(len(iq)) / fs
iq_shifted = iq * np.exp(-1j * 2 * np.pi * peak_freq * t)
# --- 低通滤波并降采样 ---
decim_factor = int(fs // target_fs)
print("降采样因子:", decim_factor)
# 简单 LPF 防混叠
lpf = firwin(129, cutoff=1/decim_factor)
iq_filt = lfilter(lpf, 1.0, iq_shifted)
iq_ds = iq_filt[::decim_factor]
fs_new = fs / decim_factor
print("新采样率:", fs_new)
# --- NFM 解调 ---
print("FM 解调中...")
audio = fm_demod(iq_ds)
# 去直流
audio = audio - np.mean(audio)
# 归一化
audio = audio / np.max(np.abs(audio))
print("写出音频到:", output_file)
sf.write(output_file, audio, int(fs_new))
print("完成!")
if __name__ == "__main__":
main()
sstv,识别一下得到flag part2

拼接一下即可得到完整flag
#wp(10)#CTF(9)评论